Mustererkennung bzw. künstliche Intelligenz wird eingesetzt, um aus akquirierten Daten die repräsentativsten Merkmale zu extrahieren und zu erkennen. Beispielhafte Anwendungen sind Spracherkennung, Gesichtserkennung, Fehlererkennung und viele mehr, welche die menschliche Wahrnehmung ständig und offensichtlich mühelos erledigt. In der Zerstörungsfreien Prüfung (ZfP) von Bauteilen und deren Komponenten entstehen große Datenmengen unterschiedlicher Modalität, die durch eine automatische Verarbeitung für den Anwender oft auf eine simple Aussage reduziert werden muss, ob ein Bauteil in Ordnung ist oder nicht. Die hohen Anforderungen an einen automatischen Prozess, der den Unterschied zwischen i.O und n.i.O Bauteile automatisch erlernen und in Überwachungssystem integriert werden kann, macht moderne Methoden der Mustererkennung unumgänglich. Der wesentliche Fortschritt durch Mustererkennung besteht darin, dass für den Menschen komplexe und aufwendige Prüfaufgaben in kürzester Zeit automatisch gelöst werden können.
Ein Mustererkennungsprozess lässt sich in mehrere Teilschritte zerlegen, bei denen am Anfang die Erfassung und am Ende eine ermittelte Klasseneinteilung steht. Zuerst werden die Daten eines Prüfszenarios mittels ZfP Sensoren, wie Ultraschall, CT, Akustik usw. aufgenommen, um eine komplette Beschreibung der zu prüfenden bzw. zu überwachenden Bauelementen zu erhalten. Aus den aufgenommenen Daten werden durch Signal-und Bildverarbeitung Algorithmen (z. B. Rekonstruktion, Filterung, Segmentierung usw.) die Merkmalen extrahiert. Aus diesen Merkmalen ist es möglich anhand von künstlicher Intelligenz (Klassifikationsverfahren) automatisierte Entscheidungen zu treffen. Eine quantitative Aussage über die Qualität des Bauelements ist mit diesem Verfahren möglich.
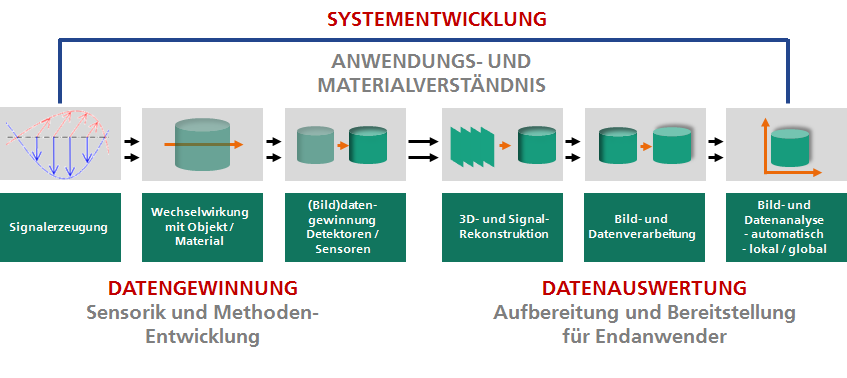 Einsatz von Bildverarbeitung und künstlicher Intelligenz für die Auswertung von Sensordaten. © Fraunhofer IZFP
Einsatz von Bildverarbeitung und künstlicher Intelligenz für die Auswertung von Sensordaten. © Fraunhofer IZFP
Beispiel:
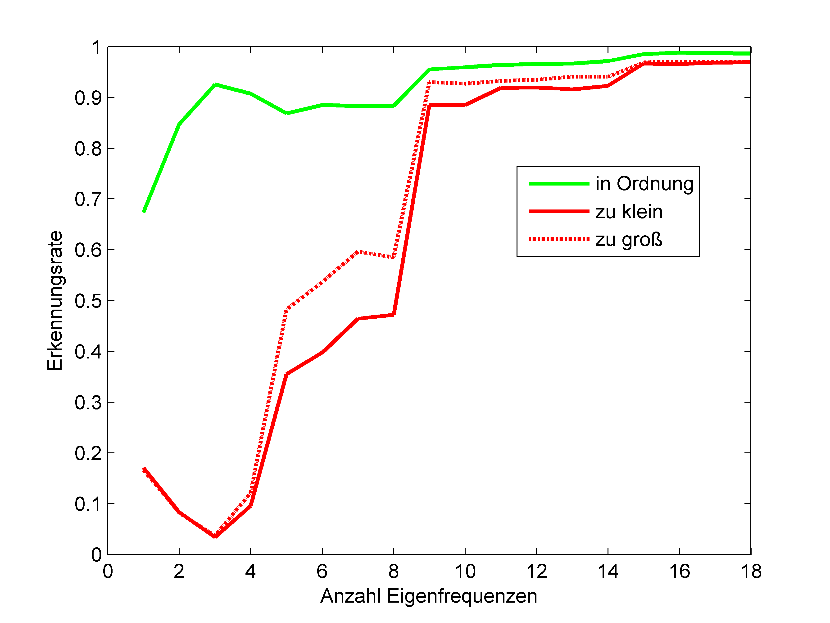
Anhand der Akustischen Resonanzanalyse wird im Folgenden die Klassifikation mittels Mustererkennung dargestellt. Hierbei ist das Ziel aus den ersten N Eigenfrequenzen einer Pleuelstangen automatisch auf bestimmte Geometrieparameter zurückzuschließen. Mit Hilfe der Musterkennung soll ein Verfahren der Merkmalsextraktion und ein Klassifikator entwickelt werden, der ein vorhandenes Testobjekt in die Klassen, „Stegbreite zu klein“, „Stegbreite im Normbereich“ und „Stegbreite zu groß“ einordnet. Die Berechnung des Klassifikators findet mit Hilfe eines Traningsdatensatzes statt, der aus einer großen Anzahl von Proben mit bekannter Klassenzugehörigkeit besteht. Dazu wurden mehrere tausend Datensätze mittels einer Finite-Elemente-Simulation erzeugt. Ganz entscheidend für die Größe des benötigten Trainingsdatensatzes ist dabei die Anzahl der verwendeten Eigenfrequenzen. Ist sie zu niedrig ist es nicht möglich daraus Rückschlüsse auf die Stegbreite zu ziehen. Ist sie zu hoch ist eine Klassifizierung zwar möglich, es müssen dann allerdings wesentlich mehr Datensätze zum Training verwendet werden. Nach Abschluss des unter Umständen aufwendigen Trainings ist der Klassifikator in der Lage in kürzester Zeit die Zuordnung die gewünschten Klassen vorzunehmen. Die Komplexität des Klassifikationsschritts ist dabei in der Regel um mehrere Größenordnungen kleiner als der Aufwand für das vorangegangen Training und daher perfekt geeignet für den Einsatz bei hoher Stückzahl.

Zur Evaluation des berechneten Klassfikators wird er auf eine größere Probenanzahl angewendet und bestimmt wie hoch die Erkennungsraten für die einzelnen Klassen sind. Es hat sich herausgestellt, dass die 15 niedrigsten Eigenfrequenzen ausreichen, um eine zuverlässige Zuordnung sicherzustellen. Im vorliegenden Beispiel wurde für alle Klassen eine Erkennungsrate von über 95% erreicht.